

- Правила поведінки і безпеки життєдіяльності (БЖ) в комп’ютерному класі. Первинний інструктаж з БЖД.
- Інструктаж з БЖД. Поняття бази даних. Поняття, призначення й основні функції систем управління базами даних.
- Інструктаж з БЖД. Поняття моделі подання даних, основні моделі подання даних.
- Інструктаж з БЖД. Проектування баз даних. Поняття сутності, атрибута, ключа, зв’язку. Модель «сутність-зв’язок» предметної області. Класифікація зв’язків за множинністю та обов’язковістю.
- Інструктаж з БЖД. Бази даних в інформаційних системах.
- Інструктаж з БЖД. Основні відомості про СУБД Access.
Таблиці - Інструктаж з БЖД. Створення й введення структури таблиць. Поняття таблиці, поля, запису. Створення таблиць, означення полів і ключів у середовищі СУБД.
- Інструктаж з БЖД. Властивості полів, типи даних.
- Інструктаж з БЖД. Модифікація структури таблиць.
- Інструктаж з БЖД. Ключові поля, індекси, зв’язування таблиць.
- Інструктаж з БЖД. Введення, пошук і редагування даних у таблиці..
- Інструктаж з БЖД. Сортування та фільтрація записів. Операції над таблицями.
- Інструктаж з БЖД. Створення структури таблиць і введення вмісту.
- Інструктаж з БЖД. Пошук, сортування і фільтрація даних у таблицях. Тематична
Запити - Інструктаж з БЖД. Загальні відомості про запити.
- Інструктаж з БЖД. Створення й виконання запитів на вибірку даних.
- Інструктаж з БЖД. Запити з функціями і з полями, що обчислюються.
- Інструктаж з БЖД. Запити з параметрами. Перехресні запити.
- Інструктаж з БЖД. Запити на змінення даних.
- Інструктаж з БЖД. Запити з функціями та з полями, що обчислюються.
- Інструктаж з БЖД. Запити з параметрами, перехресні запити і запити на змінення даних. Тематична
Форми - Інструктаж з БЖД. Створення форм за допомогою простих засобів.
- Інструктаж з БЖД. Елементи керування та властивості форм.
- Інструктаж з БЖД. Створення форм за допомогою конструктора форм.
- Інструктаж з БЖД. Використання форм для введення й редагування даних.
- Інструктаж з БЖД. Створення форм.
Звіти - Інструктаж з БЖД. Поняття звіту. Автоматичне створення звіту.
- Інструктаж з БЖД. Створення звіту за допомогою конструктора звітів.
- Інструктаж з БЖД. Створення звітів.
Основи мови запитів SQL - Інструктаж з БЖД. Призначення, основні поняття та терміни мови SQL.
- Інструктаж з БЖД. Найпростіші запити мовою SQL у системі Access.
- Інструктаж з БЖД. Запити з умовою. Групування запитів.
Імпорт та експорт об’єктів бази даних - Інструктаж з БЖД. Сутність імпорту та експорту об’єктів.
- Інструктаж з БЖД. Імпорт об’єктів з однієї бази даних в іншу.
- Інструктаж з БЖД. Експорт об’єктів з однієї бази даних в іншу.
- Інструктаж з БЖД. Виконання індивідуальних та колективних проектів.
- Інструктаж з БЖД. Виконання індивідуальних та колективних проектів.
Алгоритми і числа - Інструктаж з БЖД. Методи проектування і подання алгоритмів. Кодування алгоритмів. Поняття складності алгоритмів.
- Інструктаж з БЖД. Математична модель, вибір структури даних.
- Інструктаж з БЖД. Пошук оптимального алгоритму розв'язання
- Інструктаж з БЖД. Узагальнення та аналіз екстремальних ситуацій. Оцінка та аналіз ефективності алгоритму
- Інструктаж з БЖД. Планування, покрокова деталізація та представлення алгоритму
- Інструктаж з БЖД. Декомпозиція задачі.
- Інструктаж з БЖД. Реалізація алгоритму мовою програмування.
- Інструктаж з БЖД. Основні поняття теорії чисел: системи числення. Робота з великими числами.
- Інструктаж з БЖД. Факторизація чисел.
Алгоритми сортування і пошуку даних - Інструктаж з БЖД. Повторення вивчених структур даних. Прості змінні та масиви/списки.
- Інструктаж з БЖД. Стек.
- Інструктаж з БЖД. Черга.
- Інструктаж з БЖД. Дерево.
- Інструктаж з БЖД. Повторення вивчених методів сортування: вибором, обміном, вставкою
- Інструктаж з БЖД. Алгоритми сортування. Квадратичні алгоритми сортування. Алгоритми сортування вибором.
- Інструктаж з БЖД. Алгоритм сортування методом обміну. Сортування вставленням
- Інструктаж з БЖД. Сортування злиттям. Сортування підрахунком.
- Інструктаж з БЖД. Алгоритми пошуку даних. Послідовний пошук. Бінарний пошук.
- Інструктаж з БЖД. Пошук максимального і мінімального елементів у масиві
- Інструктаж з БЖД. Поняття про пошук із поверненням і тернарний пошук.
Обробка рядків - Інструктаж з БЖД. Обробка рядків. Основні відомості про рядки й операції над ними
- Інструктаж з БЖД. Функції і методи опрацювання рядків
- Інструктаж з БЖД. Приклади програм обробки рядків.
Графи - Інструктаж з БЖД. Основні поняття і терміни теорії графів
- Інструктаж з БЖД. Способи подання графів у комп’ютері
- Інструктаж з БЖД. Повторення вивчених методів пошуку: лінійний та бінарний пошук
- Інструктаж з БЖД. Рекурсивний пошук.
- Інструктаж з БЖД. Пошук у рядку.
- Інструктаж з БЖД. Пошук у ширину
- Інструктаж з БЖД. Пошук у глибину.
- Інструктаж з БЖД. Визначення найкоротшого шляху у графі.
- Інструктаж з БЖД. Алгоритм Дейкстри.
- Інструктаж з БЖД. Реалізація алгоритму Дейкстри.
- Інструктаж з БЖД. Алгоритм Флойда-Уоршела. Реалізація алгоритму Флойда-Уоршела.
- Інструктаж з БЖД. Розв’язування практичних завдань.
Динамічне програмування і жадібні алгоритми - Інструктаж з БЖД. Динамічне програмування. Жадібні алгоритми. Задача про рюкзак.
- Інструктаж з БЖД. Задача про коника-стрибунця. Задача про черепашку.
- Інструктаж з БЖД. Задача про розподіл ресурсів.
- Інструктаж з БЖД. Задача про оптимізацію маршруту. Найбільша спільна підпослідовність.
- Інструктаж з БЖД. Задача про центи. Задача про заявки.
- Інструктаж з БЖД. Загальна задача динамічного програмування. Критерії застосування задач динамічного програмування.
Основи обчислювальної геометрії - Інструктаж з БЖД. Базові поняття обчислювальної геометрії. Операції над векторами. Векторний добуток
- Інструктаж з БЖД. Напрям повороту при переміщенні. Обчислення площі многокутника.
Веб-технології - Інструктаж з БЖД. Історія виникнення Internet. Принципи роботи Internet.
- Інструктаж з БЖД. Передавання даних в інтернеті.
- Інструктаж з БЖД. Адресація в інтернеті.
- Інструктаж з БЖД. Веб-сторінка та веб-сайт. Домашні сторінки.
- Інструктаж з БЖД. Основні тренди у веб-дизайні.
- Інструктаж з БЖД. Види і типи сайтів. Цільова аудиторія.
- Інструктаж з БЖД. Запуск проекту «Розробка власного сайта».
- Інструктаж з БЖД. Інформаційна структура сайта.
- Інструктаж з БЖД. Системи керування вмістом
- Інструктаж з БЖД. Адміністрування сайта.
- Інструктаж з БЖД. Інструменти веб-розробника. Створення макету інформаційної структури сайта.
- Інструктаж з БЖД. Мова гіпертекстової розмітки. Поняття тегу.
- Інструктаж з БЖД. Структура HTML-Документа.
- Інструктаж з БЖД. Теги форматування тексту.
- Інструктаж з БЖД. Нумеровані і марковані списки.
- Інструктаж з БЖД. Текстові гіперпосилання.
- Інструктаж з БЖД. Використання таблиць у HTML-докуметах.
- Інструктаж з БЖД. Створення таблиці. Об’єднання комірок та налаштування.
- Інструктаж з БЖД . Встановлення ширини таблиці та комірок. Форматування тексту та оформлення рамок таблиці.
- Інструктаж з БЖД. Використання таблиць для розміщення об’єктів на веб-сторінці.
- Інструктаж з БЖД. Каскадні аркуші стилів.
- Інструктаж з БЖД. Стильове оформлення веб-сторінок з використанням CSS.
- Інструктаж з БЖД. Стильове оформлення веб-сторінок з використанням CSS.
- Інструктаж з БЖД. Створення HTML сторінок із використанням внутрішніх стилів.
- Інструктаж з БЖД. Інструктаж з БЖД. Проектування та верстка веб-сторінок.
- Інструктаж з БЖД. Блокова модель CSS.
- Інструктаж з БЖД. Графічні ефекти на CSS.
- Інструктаж з БЖД. Структурування веб-сторінки за допомогою таблиць
- Інструктаж з БЖД. Використання зображень у веб-документах. Формати зображень, які використовують в інтернеті.
- Інструктаж з БЖД.Формати зображень, які використовують в інтернеті.
- Інструктаж з БЖД. Методи створення та збереження зображень для веб-сторінок.
- Інструктаж з БЖД. Графіка для веб-середовища.
- Інструктаж з БЖД. Мультимедіа на веб-сторінках.
- Інструктаж з БЖД. Розміщення і вирівнювання зображень на веб-сторінках.
- Інструктаж з БЖД. Створення фотогалереї.
- Інструктаж з БЖД. Анімаційні ефекти. Карти посилань.
- Інструктаж з БЖД. Технології та засоби відтворення мультимедіа. Використання мультимедіа на веб-сторінках.
- Інструктаж з БЖД. Проектування та верстка веб-сторінок.
- Інструктаж з БЖД. Адаптивна верстка.
- Інструктаж з БЖД. Кросбраузерність.
- Інструктаж з БЖД. Веб-програмування та інтерактивні сторінки.
- Інструктаж з БЖД. Інтерактивні веб-сторінки на основі JavaScript, знайомство з бібліотекою jQuery.
- Інструктаж з БЖД. Інструменти розробки у браузері
- Інструктаж з БЖД. Об’єктна модель документа.
- Інструктаж з БЖД. Синтаксис мови JavaScript.
- Інструктаж з БЖД. Кнопки, події, функції.
- Інструктаж з БЖД. Тестування на JavaScript.
- Інструктаж з БЖД. Бібліотека jQuery.
- Інструктаж з БЖД. Створення слайдера.
- Інструктаж з БЖД. Хостинг сайта.
- Інструктаж з БЖД. Розміщення сайту на сервері.
- Інструктаж з БЖД. Веб-сервер і база даних.
- Інструктаж з БЖД. Взаємодія клієнт-сервер.
- Інструктаж з БЖД. Використання форм. Основні елементи форми.
- Інструктаж з БЖД. Валідація та збереження даних форм.
- Інструктаж з БЖД. Прикладний програмний інтерфейс.
- Інструктаж з БЖД. Створення та налагодження інтерактивної веб-сторінки з використанням форм та веб-програмування.
- Інструктаж з БЖД. Планування веб-сайту та етапи роботи над ним. Основні поняття дизайну.
- Інструктаж з БЖД. Правила ергономічного розміщення відомостей на веб-сторінці.
- Інструктаж з БЖД. Просторовий дизайн. Вибір розмірів сторінок.
- Інструктаж з БЖД. Компонування та визначення набору сторінок сайту. Розміщення елементів на сторінці.
- Інструктаж з БЖД. Інформаційне наповнення веб-сторінки. Підготовка тексту. Вибір шрифтового оформлення.
- Інструктаж з БЖД. Розміщення та відтворення на веб-сторінках мультимедійних даних. Відео та аудіо.
- Інструктаж з БЖД. Онлайнові конструктори сайтів.
- Інструктаж з БЖД. Колір у веб-дизайні та текстури.
- Інструктаж з БЖД. Типові помилки початківців.
- Інструктаж з БЖД. Робота у середовищі Сайти Google.
- Інструктаж з БЖД. Робота у середовищі Сайти Google.
- Інструктаж з БЖД. Робота у середовищі Strikingly.
- Інструктаж з БЖД. Робота у середовищі Webnode.
- Інструктаж з БЖД. Можливості ресурсу Mozello.
- Інструктаж з БЖД. Пошукова оптимізація та просування веб-сайтів. Можливості в епоху інтернету.
- Інструктаж з БЖД. Перші кроки на шляху до ефективної реклами в Інтернеті. Просування компанії в Інтернеті. Маркетинг вашого бізнесу в мережі.
- Інструктаж з БЖД. Аналіз і пристосування.
- Інструктаж з БЖД. Представлення компанії в Інтернеті та її місце.
- Інструктаж з БЖД. Як працює веб-сайт. Основні складові веб-сайту. Веб-сайти та комерційні цілі
- Інструктаж з БЖД. Зручність використання веб-сайту. Рекомендації щодо дизайну веб-сайту.
- Інструктаж з БЖД. Планування онлайн-стратегії бізнесу. Стратегія в Інтернеті. Як стати помітним в Інтернеті. Роль цілей у підвищенні ефективності бізнесу.
- Інструктаж з БЖД. Робота з пошуковими системами. Основні відомості про пошукові системи. Як працює пошукова система.
- Інструктаж з БЖД. Основні відомості про звичайний пошук та пошукову рекламу. Google Search Console.
- Інструктаж з БЖД. Місцевий маркетинг. Ефективність каталогів місцевих компаній.
- Інструктаж з БЖД. Використання цифрових технологій для реклами на місцевому рівні. Залучення клієнтів. Оптимізація пошукових систем для місцевих компаній.
- Інструктаж з БЖД. Основні відомості про соціальні мережі. Вибір потрібної соціальної мережі. Визначення цілей для роботи та реєстрація в соціальній мережі.
- Інструктаж з БЖД. Довгостроковий план використання соціальних мереж. Реклама в соціальних мережах. Оцінювання успіху та уникнення підводних каменів.
- Інструктаж з БЖД. Мобільна реклама. Еволюція мобільних пристроїв. Основні відомості про мобільний Інтернет і мобільні додатки.
- Інструктаж з БЖД. Вступ до контент-маркетингу. Дослідження онлайн-аудиторії.
- Інструктаж з БЖД. Контент для аудиторії онлайн. Реклама контенту та вимірювання ефективності контент-маркетингу.
- Інструктаж з БЖД. Проектна діяльність. Розбиття на групи. Вибір теми проекту. Розробка плану проекту.
- Інструктаж з БЖД. Побудова моделі даних предметної області.
- Інструктаж з БЖД. Вибір теми та підбір матеріалів для проекту.
- Інструктаж з БЖД. Робота над проектом.
- Інструктаж з БЖД. Робота над проектом.
- Інструктаж з БЖД. Представлення та захист проектів.
- Інструктаж з БЖД. Повторення і систематизація навчального матеріалу за семестр.
- Інструктаж з БЖД. Повторення і систематизація навчального матеріалу за рік
Таблиці
Запити
Форми
Звіти
Основи мови запитів SQL
Імпорт та експорт об’єктів бази даних
Алгоритми і числа
Алгоритми сортування і пошуку даних
Обробка рядків
Графи
Динамічне програмування і жадібні алгоритми
Основи обчислювальної геометрії
Веб-технології
Урок 65. Пошук в ширину
Обхід графа в ширину (приклади)
Тепер розглянемо дещо інший метод пошуку у графі, що називається пошуком в ширину. Але спочатку відмітимо, що при пошуці вглиб чим пізніше буде відвідана вершина, тим раніше вона буде використана. Це прямий наслідок того, що переглянуті, але ще невикористані вершини накопичуються в стеці. Пошук в ширину, грубо говорячи, заснований на заміні стека чергою. Після такої модифікації чим раніше відвідана вершина (поміщається в чергу), тим раніше вона використовується (видаляється з черги). Використання вершини відбувається за допомогою перегляду відразу усіх ще непереглянутих сусідів цієї вершини.
Прикладом обходу в ширину може бути поширення інформації про хворобу вчителя. Спочатку один учень, зазвичай староста, взнає про хворобу вчителя і цю важливу інформацію треба поширити серед учнів школи. Що робить учень, він іде і всім, кого зустрічає, розповідає про це. Потім всі ті, кому відома ця інформація, зустрічають інших, кому ще невідома ця інформація, і повідомляють її. Інформація поширюється майже миттєво.
Розглянемо попередні графи і здійснимо для них обхід в ширину.
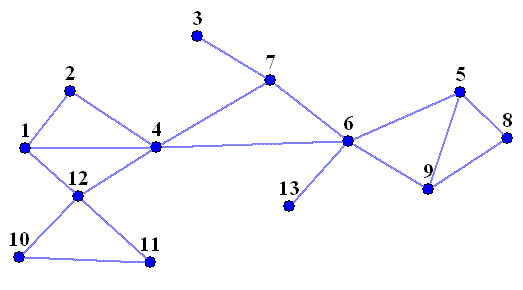
Почнемо знову з 1-ої вершини. 1-а вершина зв'язана з 2, 4 і 12-ою. Їх ще називають «дітьми». Дивимося, які вершини сумісні з «дітьми»: 2-а вершина ні з якою новою (нерозглянутою ще) вершиною не сумісна, 4-а пов'язана з 6-ою і 7-ою, 12-а зв'язана з 10-ою і 11-ою. Всі ці вершини називають «дітьми дітей» або «онуками». Далі розглядаємо всі нові вершини, які сумісні з «онуками»: 6-а пов'язана з 5-ою, 9-ою і 13-ою; 7-а - з 3-ою; 10-а та 11-а несумісні ні з якими новими вершинами. Вершини 5, 9, 13 і 3 є «правнуками», на наступному кроці 5-а вершина сумісна з 8-ою. Обхід графа в ширину можна завершити, бо ми обійшли вже всі вершини.
На малюнку у дужках подана нумерація вершин по черзі, в якій вершини переглядаюся у процесі пошуку в ширину; вершини- «діти» позначені жовтим кольором, вершини - «онуки» - зеленим, «правнуки» - блакитним, і нарешті «праправнуки» - синім.
Як ми вже казали, обхід в ширину використовує чергу. Черга - структура даних з короткою характеристикою типу «першим прийшов - першим пішов» (first-in, first-out -- FIFO).
Це здається більш чесним, ніж останнім ввійшов, першим вийшов (особливість стеку), саме тому черги у магазинах реалізовані як черги, а не як стеки. Колоди гральних карт можуть бути змодельовані чергами, оскільки ми здаємо карти зверху колоди, а після поміщуємо їх під низ.
Черги реалізуються складніше, ніж стеки, тому що дія відбувається на обох кінцях цієї структури. Найпростіша реалізація черги використовує також масив (таблиця).
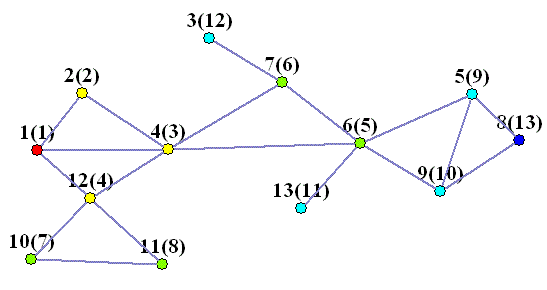
На попередньому малюнку в дужках також нумерація порядку, в якому вершини потрапляють у чергу.
На прикладі 2 покажемо як черга допомагає при обході в ширину.
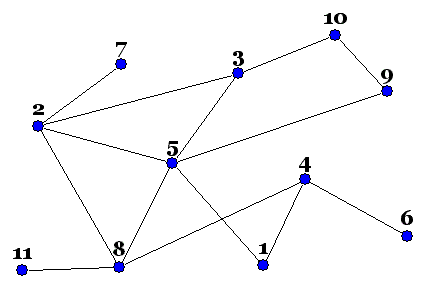
Покладемо 8 вершину у чергу
| 8 |
Працюємо з 8-ою вершиною. Оскільки вона суміжна з 2-ою, 4-ою, 5-ою та 11-ою вершинами, то в порядку зростання їх номера заносимо їх у чергу.
| 11 |
| 5 |
| 4 |
| 2 |
| 8 |
Переходимо до розгляду 2-ої вершини.
| 11 |
| 5 |
| 4 |
| 2 |
| 8 |
Вона суміжна з 3-ою, 5-ою, 7-ою і 8-ою, але 8-а і 5-та вже є у черзі, отже вже не є новими, тому на вершину черги заносимо 3-ю та 7-у вершини. І переходимо до розгляду 4-ої вершини.
| 7 |
| 3 |
| 11 |
| 5 |
| 4 |
| 2 |
| 8 |
4-а вершина з'єднана ребром з 1-ою, 6-ою та 8-ою. 8-а вершина вже є у черзі, тому на вершину черги заносимо спочатку 1-у, а потім 6-у вершини. Переходимо до розгляду 5-ої вершини.
| 6 |
| 1 |
| 7 |
| 3 |
| 11 |
| 5 |
| 4 |
| 2 |
| 8 |
5-а вершина сумісна лише з однією вершиною 9-ою, якої ще не було в черзі. І переходимо до розгляду 11-ої вершини.
| 9 |
| 6 |
| 1 |
| 7 |
| 3 |
| 11 |
| 5 |
| 4 |
| 2 |
| 8 |
11-а вершина зв'язана ребром тільки з 8-ою вершиною, яка вже є в черзі. Переходимо до розгляду 3-ої вершини.
| 9 |
| 6 |
| 1 |
| 7 |
| 3 |
| 11 |
| 5 |
| 4 |
| 2 |
| 8 |
3-я вершина пов'язана лише з однією новою вершиною - 10-ою. Заносимо її у вершину черги.
| 10 |
| 9 |
| 6 |
| 1 |
| 7 |
| 3 |
| 11 |
| 5 |
| 4 |
| 2 |
| 8 |
Ми можемо переходити до наступної вершини, але оскільки вже всі одинадцять вершин у черзі, то нової вершини на вершині черги не з'явиться. Обхід в ширину завершений.
Отже, обхід в ширину має відправний вузол Х, а процес його являє ніби хвилю, що поширюється у графі від «точки збурення» Х та захоплює все нові вузли. Після вузла Х опрацьовуються усі вузли, суміжні з Х - «діти» Х, потім «діти дітей» - «внуки» Х тощо. У зв'язному графі всі вузли будуть опрацьовані.
Вершини - «діти» - це вершини, до яких «можна дійти» від відправного вузла Х за допомогою одного ребра, вершини - «онуки» - це вершини, до яких можна дістатися з Х за допомогою двох ребер тощо.
Зробимо ще деякі висновки:
При використанні пошуку в ширину, як і у випадку пошуку вглиб, ми відвідуємо усі вершини зв'язаної компоненти графа. Ми розглядали зв'язні графи. При обході вглиб або в ширину виявилось в стеці чи черзі побували всі вершини графа. Саме це є ознакою зв'язності графа.
Для того, щоб у цьому переконатися, розглянемо незв'язний граф. І здійснимо, наприклад, обхід в ширину.
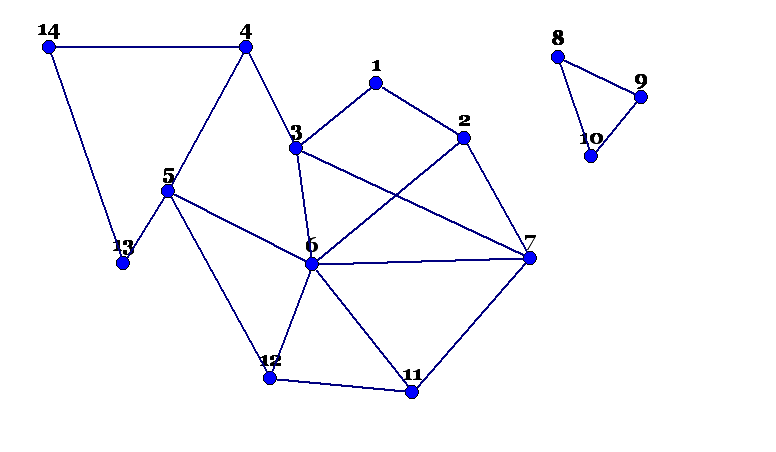
Можемо почати з будь-якої вершини. Це не має значення. Оберемо, наприклад 5-у вершину. Проробіть самостійно обхід в ширину і перевірте результат - послідовність вершин, в якій вони потрапляють у чергу
|
|
| 1 |
| 11 |
| 7 |
| 2 |
| 14 |
| 3 |
| 13 |
| 12 |
| 6 |
| 4 |
| 5 |
Вершини 8, 9 та 10 ніколи не потраплять у чергу, бо жодна з вершин, що вже у черзі є несумісна з жодною з перерахованих.
Якби ми почали з, наприклад, 9-ої чи 11 вершин, то черга виглядала інакше, але висновок був би таким самим - граф незв'язний.
В чергу потрапила лише частина вершин графа, яка разом з ребрами, що ці вершини з'єднують, є зв'язною. Будь-який граф можна розглядати як деяку сукупність зв'язним графів. Кожний з цих графів називатимемо компонентою зв'язності вихідного графа.
В останньому графі таких компонент зв'язності є дві. Довільний зв'язний граф має одну компоненту зв'язності.
Отже, за допомогою обходів графа в ширину чи вглиб можна перевірити, чи він є зв'язним. Саме цим ми скористаємося на наступних уроках.
Інформація з https://disted.edu.vn.ua/courses/learn/278
_______________________________________________________________________________________________________________________
Покрокова деталізація, планування та представлення алгоритму. Допоміжні задачі. Реалізація мовою програмування.
Оскільки для вирішення вихідної задачі застосовують деяку математичну модель, то тим самим можна формалізувати алгоритм вирішення в термінах цієї моделі. У початкових версіях алгоритму часто застосовуються узагальнені оператори, які потім перевизначаться у вигляді більш дрібних, чітко визначених інструкцій. Але для перетворення неформальних алгоритмів у комп’ютерні програми необхідно пройти через декілька етапів формалізації (цей процес називають покроковою деталізацією), поки не отримають програму, яка повністю складається з формальних операторів мови програмування.
В основу процесу проектування програми з розбиттям її на достатню кількість дрібних кроків можна покласти наступну послідовність дій:
1. Вихідним станом процесу проектування є більш-менш точне формулювання мети алгоритму, або конкретніше – результату, який повинен бути отриманий при його виконанні. Формулювання проводиться на природній мові.
2. Проводиться збір фактів, які стосуються будь-яких характеристик алгоритму, і робиться спроба їх представлення засобами мови.
3. Створюється образна модель процесу, який відбувається, використовуються графічні та інші способи представлення, образні „картинки”, які дозволяють краще зрозуміти виконання алгоритму в динаміці.
4. В образній моделі виділяється найбільш суттєва частина, для якої підбирається найбільш точне словесне формулювання.
5. Проводиться визначення змінних, які необхідні для формального представлення даного кроку алгоритму.
6. Вибирається одна з конструкцій – проста послідовність дій, умовна конструкція або циклу. Складні частини вибраної формальної конструкції (умова, заголовок циклу) залишаються в словесному формулюванні.
7. Для інших неформалізованих частин алгоритму, які залишились у словесному формулюванні – перерахована послідовність дій повторюється.
Зовнішня сторона такого процесу проектування програми полягає в тому, що одне словесне формулювання алгоритму замінюється на одну з трьох можливих конструкцій мови, елементи якої продовжують залишатися в неформальному, словесному формулюванні. Проте, це зовнішня сторона процесу. Насправді, кожне словесне формулювання алгоритму містить важливий перехід, який виконується в голові програміста і не може бути формалізованим – перехід від мети (результату) роботи програми до послідовності дій, які приводять до потрібного результату. Тобто алгоритм вже формулюється, але тільки з використанням образного мислення і природної мови.
Складність алгоритму. У процесі вирішення прикладних задач вибір потрібного алгоритму викликає певні труднощі. І справді, на чому базувати свій вибір, якщо алгоритм повинен задовольняти наступні протиріччя.
1. Бути простим для розуміння, перекладу в програмний код і наладки.
2. Ефективно використовувати комп’ютерні ресурси і виконуватися швидко.
Якщо написана програма повинна виконуватися лише декілька разів, то перша вимога найбільш важлива. Вартість робочого часу програміста, звичайно, значно перевищує вартість машинного часу виконання програми, тому вартість програми оптимізується за вартістю написання (а не виконання) програми. Якщо мати справу з задачею, вирішення якої потребує значних обчислювальних затрат, то вартість виконання програми може перевищити вартість написання програми, особливо якщо програма повинна виконуватися багаторазово. Тому, з економічної точки зору, перевагу буде мати складний комплексний алгоритм (в надії, що результуюча програма буде виконуватися суттєво швидше, ніж більш проста програма). Але і в цій ситуації розумніше спочатку реалізувати простий алгоритм, щоб визначити, як повинна себе вести більш складна програма. При побудові складної програмної системи бажано реалізувати її простий прототип, на якому можна провести необхідні виміри й змоделювати її поведінку в цілому, перш ніж приступати до розробки кінцевого варіанту. Таким чином, програмісти повинні бути обізнані не тільки з методами побудови швидких алгоритмів, але й знати, коли їх потрібно застосувати.
Існує декілька способів оцінки складності алгоритмів. Програмісти, звичайно, зосереджують увагу на швидкості алгоритму, але важливі й інші вимоги, наприклад, до розмірів пам’яті, вільного місця на диску або інших ресурсів. Від швидкого алгоритму може бути мало толку, якщо під нього буде потрібно більше пам’яті, ніж встановлено на комп’ютері.
Важливо розрізняти практичну складність, яка є точною мірою часу обчислення і об’єму пам’яті для конкретної моделі обчислювальної машини, і теоретичну складність, яка більш незалежна від практичних умов виконання алгоритму і дає порядок величини вартості.
Більшість алгоритмів надає вибір між швидкістю виконання і ресурсами. Задача може виконуватися швидше, використовуючи більше пам’яті, або навпаки – повільніше з меншим обсягом пам’яті.
Прикладом в даному випадку може слугувати алгоритм знаходження найкоротшого шляху. Задавши карту вулиць міста у вигляді мережі, можна написати алгоритм, що обчислює найкоротшу відстань між будь-якими двома точками цієї мережі. Замість того, щоб кожного разу заново перераховувати найкоротшу відстань між двома заданими точками, можна наперед прорахувати її для всіх пар точка і зберегти результати в таблиці. Тоді, щоб знайти найкоротшу відстань для двох заданих точка, достатньо буде просто взяти готові значення з таблиці. При цьому отримують результат, практично, миттєво, але це зажадає великий обсяг пам’яті. Карта вулиць для великого міста може містити сотні тисяч точок. Для такої мережі таблиця найкоротших відстаней містила б більше 10 мільярдів записів. В цьому випадку вибір між часом виконання і обсягом необхідної пам’яті очевидний.
Із цього зв’язку випливає ідея просторово-часової складності алгоритмів. При цьому підході складність алгоритму оцінюється в термінах часу і простору, і знаходиться компроміс між ними.
При порівнянні різних алгоритмів важливо розуміти, як складність алгоритму співвідноситься із складністю вирішуваної задачі. При розрахунках за одним алгоритмом сортування тисячі чисел може зайняти 1 секунду, а сортування мільйона – 10 секунд, тоді як розрахунки за іншими алгоритмами можуть зайняти 2 і 5 секунд відповідно. У цьому випадку не можна однозначно сказати, яка із двох програм краща – це буде залежати від вихідних даних.
Ефективність алгоритмів
Одним із способів визначення часової ефективності алгоритмів полягає в наступному: на основі даного алгоритму потрібно написати програму і виміряти час її виконання на певному комп’ютері для вибраної множини вхідних даних. Хоча такий спосіб популярний і, безумовно, корисний, він породжує певні проблеми. Визначений час виконання програми залежить не тільки від використаного алгоритму, але й від архітектури і набору внутрішніх команд даного комп’ютера, від якості компілятора, і від рівня програміста, який реалізував даний алгоритм. Час виконання також може суттєво залежати від вибраної множини тестових вхідних даних. Ця залежність стає очевидною при реалізації одного й того ж алгоритму з використанням різних комп’ютерів, різних компіляторів, при залучені програмістів різного рівня і при використанні різних тестових даних. Щоб підвищити об’єктивність оцінки алгоритмів, учені, які працюють в галузі комп’ютерних наук, прийняли асимптотичну часову складність як основну міру ефективності виконання алгоритму.
Практична робота №41
"Оцінка сайту. Просування сайту"
Проведення оцінки сайту може допомогти власнику в з’ясуванні проблем, які можуть заважати йому просувати його в пошукових системах. Також технічний та SEO аналіз дозволяє отримати важливі дані, такі як число проіндексованих сторінок, положення в пошукових системах, дублі сторінок, неправильні редіректи, незаповнені мета-теги та інші важливі критерії, які суттєво впливають на ранжування сторінок. Існує ряд ресурсів, які дозволяють безкоштовно провести аналіз сайту і заощадити на фахівцях тисячі гривень.
Завдання.
- Ознайомтеся з сервісами для безкоштовного аналізу сайта онлайн.
- За допомогою одного із них проведіть аналіз сайту нашої школи.
- За результатами дослідження створіть текстовий документ, розмістіть на своєму гугл-диску та надішліть посилання вчителю.
Форми в HTML
Параметри тега <FORM>
Для створення форми на Web-сторінці в HTML-документі використовується тег-контейнер <FORM> . . . </FORM>. Його вмістом є теги <INPUT>, <TEXTAREA> <SELECT>, які призначені для створення різних органів управління форми (полів вводу даних, кнопки, перемикачі та ін.).
Тег <FORM>містить наступні параметри:
- ACTION - вказує URL-адреса програми (CGI-програми для виконання дій над формою;
- METHOD - вказує один з двох основних способів передачі даних від форми на сервер:
- GET - CGI-додаток отримує дані з форми на Web-сторінці через змінну середовища з ім'ям QUERY_STRING;
- POST - CGI-додаток отримує дані з форми на Web-сторінці через стандартний потік вводу
- ENCTYPE - вказує MIME-тип передачі даних.
Параметри тега <INPUT>
Тег <INPUT> містить такі параметри:
- TYPE - вказує тип органу управління, його значеннями є:
- text - однорядкове поле для введення текстової інформації; розмір поля і число символів визначається значенням SIZE та MAXLENGTH тега <INPUT>
- textarea - многострокове поле для введення текстової інформації; розмір поля і число символів визначається значенням SIZE та MAXLENGTH тега <INPUT> (для введення багаторядкових даних предподчтительнее використовувати тег <TEXTAREA>);
- password - для введення пароля, аналогічний параметру text , але текст, введений користувачем не відображається на екрані;
- checkbox - незалежний перемикач;
- radio - перемикач, що залежить від стану інших перемикачів, використовується для вибору одного значення з декількох;
- file - для вибору і передачі файлу;
- button кнопка із заданою підписом;
- submit - кнопка, предначначенная для надсилання даних з заповненої форми Web-серверу;
- - має таке ж начначение, що і параметр submit , але у вигляді зображення;
- hidden - приховане поле, не відображається на екрані, але може бути передано сервера.
- NAME - вказує ім'я органу управління, надсилається програмі обробки форми;
- VALUE - вказує значення або стан органу управління;
- CHECKED - використовується для встановлення початкового стану перемикачів;
- SIZE - вказує ширину поля для введення текстової інформації, за замовчуванням приймається рівним 20;
- MAXLENGTH - вказує максимальну кількість символів, які може бути введено в даному полі, за замовчуванням не має обмежень;
- ALIGN - вказує вирівнювання тексту біля форми;
- SRC - URL-адреса графічного зображення, якщо воно використовується в органі управління.
прикладі № 1 показано завдання полів форми на Web-сторінці за допомогою тега <INPUT>.
Параметри тега <TEXTAREA>
Для введення багаторядкового тексту краще скористатися тегом-контейнером <TEXTAREA> . . . </TEXTAREA>, для якого можна встановити наступні три параметри:
- NAME - вказує ім'я багаторядкового поля, надсилається програмі обробки форми;
- ROWS - вказує розмір поля по вертикалі (в рядках);
- COLS - вказує розмір поля по горизонталі (стрічки).
прикладі № 1 показано завдання полів форми на Web-сторінці за допомогою тега <TEXTAREA> .
Параметри тега <SELECT>
За допомогою тега-контейнера <SELECT> . . . </SELECT> можна вказати у формі на Web-сторінці заздалегідь проинициализированный список довільних текстових рядків. Обрана рядок або вибрані рядки передаються Web-серверу поряд з вмістом інших полів форми. Для тегу <SELECT> визначені наступні параметри:
- NAME - вказує ім'я списку, яке разом з обраної рядком передається серверу;
- SIZE - вказує кількість рядків списку, що відображаються на екрані, решта згорнуті і для появи на екрані вимагають прокручування списку;
- MULTIPLE - вказує на те, що можуть бути відзначені і передані на сервер не один рядок, а всі зазначені.
Кожен рядок списку всередині контейнера <SELECT> . . . </SELECT> задається за допомогою тега <OPTION>, який містить наступні параметри:
- SELECTED - відзначає спочатку вибраний рядок;
- VALUE - задає значення вибраної рядка.
Нижче наводиться приклад використання тегу <SELECT>, в якому задається набір з черырех рядків. На екрані відображаються два рядки: "Example1_2" і "Example1_3", перша з них ("Example1_2") відзначається як обрана. Для доступу до двох інших рядках необхідно виконати прокручування. Відзначити можна будь-яке число рядків з заданого набору.
Кожна зазначена рядок передається на сервер у вигляді пари "ім'я=значення". В якості імені береться ім'я набору, тобто. "number". В якості значення береться значення параметра VALUE, а якщо він не вказаний - текст після тега <OPTION>. Наприклад, для другого рядка на Web-сервер передається пара "number=second", а для третьої рядка, якщо вона буде обрана, - "number=Example1_3".
<SELECT NAME="number" SIZE=2 MULTIPLE>
<OPTION VALUE="first"> Example_1
<SELECTED OPTION VALUE="second"> Example1_2
<OPTION> Example1_3
<OPTION VALUE="fourth"> Example1_4
</SELECT>
прикладі № 1 показано використання і тега <SELECT>на Web-сторінці.
Інтерфейс CGI
Як вже зазначалося вище, інтерфейс CGI призначений для обробки даних, заданих на стороні клієнта у вигляді форми на Web-сторінці, за допомогою програми (CGI-програми), розташованої на сервері. Дані та імена полів передаються на сервер в такому форматі:
Имя1 = Значення1&Имя2=Значення2& . . .
При цьому використовується так звана URL-кодування. В цій кодіровці всі символи пробілів замінюються символом "+". Крім того, для подання кодів керуючих клавіш і деяких інших (до їх числа потрапили символи кирилиці) використовується послідовність символів виду %xx, де символи xx являють собою 16-ричный код у вигляді двох ASCII-символів.
Порядок обробки форми при використанні CGI-інтерфейсу:
- Користувач заповнює форму на Web-сторінці і натискає кнопку з типом submit (прикладі № 1 вона має ім'я "ПЕРЕДАЧА").
- Браузер аналізує URL-адреса CGI-додатки, заданий у параметрі ACTION форми і встановлює з'єднання з відповідним Web-сервером (як Web-сервера може бути використаний, наприклад сервер Apache).
- Web-сервер перетворює URL-адреса в шлях до файлу на комп'ютері і визначає, що URL-адреса вказує на CGI-додаток, а не на статичний файл.
- Web-сервер готує змінні оточення і запускає CGI-додаток на виконання.
- Ця програма відповідно до заданого методом передачі даних на сервер (GET або POST) визначає змінні оточення і зчитує дані у вигляді пар "ім'я=значення", здійснюючи, якщо необхідно, їх перекодування.
- Програма виводить на стандартний потік виводу HTTP-заголовок і результати обробки даних форми у вигляді динамічно створеного HTML-документа.
- Web-сервер передає браузеру отриманий документ і закриває з ним з'єднання.
- Браузер відображає отримані дані на екрані у вигляді Web-сторінок.
У прикладі №1 наведено HTML-документ, який реалізує на екрані різні види органів управління форми, заданої на Web-сторінці.
Клацнувши по кнопці "Приклад №1", можна побачити на екрані форму з полями введення однорядкової і багаторядкової текстової інформації, з полем вводу пароля, з залежними і незалежними перемикачами, з полем вибору елементів списку, з кнопками "ЩОБ" і "ПЕРЕДАЧА". В якості параметра ACTION вказано URL-адреса "http://172.17.72.25/cgi-bin/form_cgi.exe". Це адреса програми "form_cgi.exe", яка знаходиться на сервері з IP-адресою 172.17.72.25, є CGI-додатком і призначена для обробки полів форми. Якщо ця програма не розроблено, а також у разі, коли сервер вимкнений або не налаштований для перевірки роботи кнопки "ПЕРЕДАЧА" в якості параметра ACTION можна вказати адресу одного з файлів з HTML-документом, наприклад, prim2-1.htm:
<FORM METHOD=get ACTION= "prim2-1.htm">
<HTML>
<HEAD>
<TITLE> Форми в HTML на Web-сторінці </TITLE>
<LINK REL=stylesheet HREF=""> <STYLE>
.form{background:#a0ffff;color:#004000;font-size:6mm}
.kn{background:#e0e0ff; border:outset 4 blue; font-size:4,5 мм}
</STYLE>
</HEAD>
<BODY>
<FORM METHOD=get ACTION= "http://172.17.72.25/cgi-bin/form_cgi.exe">
<TABLE ALIGN=center STYLE="color:#000080; font-size:6mm">
<TR> <TD VALIGN=top> Поле вводу однорядкової текстової інформації <BR> (text);
<TD><INPUT TYPE=text NAME="txt1" VALUE="Рядок тексту" SIZE=15 CLASS="form">
<TR> <TD VALIGN=top> Полі введення пароля <BR> (password)
<TD><INPUT TYPE=password NAME="pass"
VALUE="www" SIZE=15 MAXLENGTH=3 CLASS= "form">
<TR> <TD VALIGN=top> Поле вводу багаторядкової текстової інформації <BR> (textarea)
<TD><TEXTAREA NAME="txt2" ROWS=3 CLASS= "form">
пМногострочная інформація</TEXTAREA>
<TR> <TD VALIGN=> top; Незалежні перемикачі <BR> (checkbox)
<TD><INPUT TYPE=checkbox NAME="ch1" VALUE="on" CHECKED>1 <BR>
<INPUT TYPE=checkbox NAME="ch2" VALUE="on" >2<BR>
<INPUT TYPE=checkbox NAME="ch3" VALUE="on" CHECKED>3<BR>
<TR> <TD VALIGN=top> Залежні перемикачі <BR> (radio)
<TD><INPUT TYPE=radio NAME="rad" VALUE= "on1" CHECKED> <BR>
<INPUT TYPE=radio NAME="rad" VALUE= "on2"> Другий <BR>
<INPUT TYPE=radio NAME="rad" VALUE= "on3"> Третій <BR>
<TR><TD VALIGN=top> Вибір із списку <BR> (select)
<TD><SELECT NAME="sel" SIZE=1 MULTIPLE CLASS="form">
<OPTION VALUE="first"> Приклад №1
<SELECTED OPTION VALUE="second"> Приклад №2
<OPTION VALUE="third"> Приклад №3
<OPTION VALUE="fourth"> Приклад №4
</SELECT>
</TABLE>
<P ALIGN=center><INPUT TYPE=reset VALUE= "СКИДАННЯ" CLASS="kn">
<INPUT TYPE=submit VALUE="ПЕРЕДАЧА" CLASS="kn">
</FORM>
</BODY>
</HTML>
Перед тим як "натиснути" кнопку "ПЕРЕДАЧА", здійснивши передачу даних з форми CGI-додаток і його запуск для обробки даних, необхідно виконати наступне:
1. Всі файли, що містять HTML-документи з використанням CGI-інтерфейсу, повинні знаходиться в підкаталозі "C:\Temp\Apache". Це обмеження пов'язано з налаштуваннями Web-сервера Apache і тим, хто не має достатнього практичного досвіду роботи з цим сервером, краще не займатися зміною його параметрів. Тому файл "prim5-1.htm", що містить, наведений у прикладі №1 HTML-документ, а також всі створені файли, що містять документи з використанням CGI-інтерфейсу, повинні бути скопійовані в папку "C:\Temp\Apache".
2. Необхідно розробити CGI-додаток, що обробляє дані з форми, у вигляді виконавчого файлу з ім'ям, зазначеним у параметрі ACTION форми (у прикладі №1 - це файл "form_cgi.exe"). Цей файл повинен бути поміщений в підкаталог "C:\Temp\Apache\cgi-bin". Ця умова також пов'язано з налаштуваннями Web серверу. Зазначимо, що в параметрі ACTION необхідно вказувати повну адресу файлу, включаючи IP-адреса сервера, як показано в прикладі №1 для комп'ютера №5 (для комп'ютера №4 IP-адреса буде 172.17.72.24 і т.д.).Поняття алгоритму. Декомпозиція
Декомпозиція при програмуванні має на меті розкладання складної проблеми (задачі) на простіші, інтеграція – реалізацію складної проблеми (задачі) вищого рівня за допомогою проблем (задач) нижчого рівня. Кроків декомпозиції може бути декілька, тобто проблема (задача) деякого рівня декомпозиції може підлягати подальшій декомпозиції. Цей процес породжує ієрархію проблем (задач, виконавців). Декомпозиція при розробці програми породжує ієрархічну структуру програми.
Ієрархічній структурі програми відповідає ієрархія абстрактних виконавців – ієрархія дій, даних, керування. Для кожного абстрактного виконавця ієрархії будується алгоритм відповідного рівня абстракції. При побудові такого алгоритма треба використовувати структури керування й структри абстрактних даних.
При розробці програми для структур керування й структур даних використовуються певні засоби зображення. Одним з основних понять у програмуванні є поняття алгоритма. Слово «алгоритм» походить від «algorithmi» — латинської форми написання імені великого математика Аль-Хорезмі, який сформулював правила виконання арифметичних дій. Тому спочатку під алгоритмом розуміли тільки правила виконання чотирьох арифметичних дій над багатоцифровими числами в десятковій системі числення. На даний час це поняття є одним із фундаментальних понять інформатики.
Оцінка ефективності алгоритму
З кожним алгоритмом, зазвичай, зв'язується інтуїтивне представлення про його складність. Однак, інтуїтивне представлення не дозволяє однозначно вибрати для вирішення конкретної задачі один із множини еквівалентних алгоритмів або визначити можливість застосування даного алгоритму для її вирішення. Тому важливою є формалізація оцінки складності алгоритмів.
Складність алгоритму — це кількісна оцінка ресурсів, що витрачаються алгоритмом. В якості ресурсів можна розглядати людські (на створення і розуміння алгоритму) і обчислювальні (на виконання алгоритму) ресурси. Тому розрізняють описову (інтелектуальну) і обчислювальну складність алгоритму.
Описова складність визначається виходячи з самого запису (тексту) алгоритму. Єдиного критерію її оцінки не існує. Зазвичай, описова складність характеризується довжиною запису алгоритму.
Як обчислювальні ресурси для виконання алгоритму розглядають пам'ять і процесорний час. Тому основними мірами обчислювальної складності алгоритмів є:
ємнісна (просторова) складність, яка характеризує кількість пам'яті, необхідної для виконання алгоритму;
часова складність, яка характеризує кількість часу, необхідного на виконання алгоритму (цей час, як правило, визначається кількістю елементарних операцій, які потрібно виконати для реалізації алгоритму).
Як відомо, комп'ютери мають обмежений обсяг пам'яті. Якщо дві програми реалізують ідентичні функції, то та, яка використовує менший обсяг пам'яті, характеризується меншою ємнісною складністю. Іноді пам'ять є домінуючим чинником в оцінці ефективності програм. Однак в останні роки у зв'язку із швидким її здешевленням ця складова ефективності поступово втрачає своє значення.
Для оцінки часової складності можна просто запустити кожен алгоритм на декількох задачах і порівняти час виконання. Інший спосіб - математично оцінити час виконання підрахунком операцій.
У цьому випадку складність алгоритму (і часова, і ємнісна) описується функцією f(n), де n - розмір вхідних даних (розмірність оброблюваного масиву, кількість слів в тексті, що аналізується, довжина послідовності в алгоритмі, число вершин оброблюваного графа тощо).
Знаходження точної залежності f(n) для конкретного алгоритму - задача досить складна. Найчастіше така докладна оцінка і не потрібна. З цієї причини зазвичай обмежуються лише асимптотичними оцінками швидкості росту цієї функції, які описують граничну поведінку складності алгоритму при збільшенні n (наскільки швидко або повільно зростає ця функція).
Загалом використовується декілька підходів, які виражають так званий порядок складності алгоритму. В їх основі лежить порівняння функції f(n) з якою-небудь функцією, чия поведінка добре досліджена.
Зокрема, розрізняють верхні (О), нижні (![]() ) і ефективні (
) і ефективні (![]() ) асимптотичні оцінки (рис. 1).
) асимптотичні оцінки (рис. 1).
|
|
|
c>0, n0>0: 0 f(n) c*g(n), n>n0 | c>0, n0 >0 : 0 c*g(n) f(n) | f(n)= |
а) - верхні | б) нижні | в) ефективні |



Рис. 1. Асимптотичні оцінки складності алгоритму
Найбільш популярною для оцінювання складності алгоритмів є верхня оцінка - О-нотація. Її позначення: f(n) = О(g(n)).
Ця нотація дозволяє враховувати у функції f(n) лише найбільш значущі елементи, відкидаючи другорядні.
Розглянемо алгоритм обчислення значення багаточлена степеня n в заданій точці x :
Pn(x) = anxn + an-1xn-1 + ... + aixi + ... + a1x1 + a0.
Алгоритм 1. Для кожного доданка, окрім a0, піднести x в задану степінь послідовним множенням і домножити на коефіцієнт. Потім доданки скласти.
Обчислення i-го доданку (i = 1 .. n) даним алгоритмом вимагає i множень. Значить, всього 1 + 2 + 3 + ... + n = n(n +1)/2 множень. Крім того, потрібно n +1 додавання. Всього n(n+1)/2 + n + 1 = n2/2 + 3n/2 + 1 операцій.
Алгоритм 2. Винесемо x за дужки і перепишемо багаточлен у вигляді
Pn(x) = a0+ x (a1+ x (a2+ ... x (ai+ .. x (an-1 + anx )))).
Наприклад ,
P3(x) = a3x3 + a2x2 + a1x1 + a0 = a0 + x (a1 + x (a2 + a3x)).
Будемо обчислювати вираз зсередини. Сама внутрішня дужка вимагає 1 множення і 1 додавання. Її значення використовується для наступної дужки. І так, 1 множення і 1 додавання на кожну дужку, яких n-1 штука. І ще після обчислення самої зовнішньої дужки помножити на x і додати a0. Всього n множень + n додавань = 2n операцій.
У функції f(n) = n2/2 + 3n/2 + 1 при досить великих n компонента n2 буде значно перевершувати інші складові, і тому характерна поведінка цієї функції визначається саме цією компонентою. Інші компоненти (порівняно повільно зростаючий доданок 3n/2 +1 і константний множник 1/2) можна відкинути і умовно записати, що дана функція має оцінку поведінки (в сенсі швидкості росту її значень) виду О(n2) [ читається як "О велике від ен квадрат"]. Фраза «складність алгоритму є О(n2)» означає, що при великих n час роботи алгоритму (або загальна кількість операцій) не більше ніж c · n2, де c - якась додатна константа.
Таким чином, O() - "урізана" оцінка часу роботи алгоритму, яку часто набагато простіше отримати, ніж точну формулу для кількості операцій.
Важливе теоретичне і практичне значення має класифікація алгоритмів, яка бере до увагу швидкість зростання цієї функції.
Виділяють такі основні класи алгоритмів:
лінійні: O(n)
Лінійне зростання — подвоєння розміру задачі подвоїть і необхідний час. При n = 1, тобто O(1) - сталий час роботи незалежно від розміру задачі.
логарифмічні: O(logn)
Логарифмічне зростання — подвоєння розміру задачі збільшує час роботи на сталу величину
поліноміальні: O(nm), де m - натуральне число, більше від одиниці (при m = 1 алгоритм є лінійним)
Квадратичне зростання — подвоєння розміру задачі вчетверо збільшує необхідний час.
Кубічне зростання — подвоєння розміру задачі збільшує необхідний час у вісім разів.
експоненційні: O(сn), де с - натуральне число, більше від одиниці
Експоненційне зростання — збільшення розміру задачі на 1 призводить до c-кратного збільшення необхідного часу; подвоєння розміру задачі підносить необхідний час у квадрат.
Для однієї й тієї ж задачі можуть існувати алгоритми різної складності. Наприклад, для попередньої задачі алгоритм 1 має складність О(n2), алгоритм 2 - О(n).
Часто буває і так, що більш повільний алгоритм працює завжди, а більш швидкий - лише за певних умов.
Правила формування оцінки O( ):
При оцінці за функцію береться кількість операцій, що зростає найшвидше.
Тобто, якщо в програмі одна функція, наприклад, множення, виконується O(n) разів, а додавання - O(n2) разів, то загальна складність програми - O(n2), оскільки при збільшенні n додавання стануть виконуватися настільки часто, що будуть впливати на швидкодію куди більше, ніж множення.
При оцінці O( ) константи не враховуються.
Нехай один алгоритм робить 2500n + 1000 операцій, а інший - 2n +1. Обидва вони мають оцінку O(n), так як їхній час виконання зростає лінійно.
Інший наслідок опускання константи - алгоритм з часом O(n2) може працювати значно швидше алгоритму O(n) при малих n. За рахунок того, що реальна кількість операцій першого алгоритму може бути n2 + 10n + 6, а другого - 1000000n + 5. Втім, другий алгоритм рано чи пізно обжене перший, оскільки n2 росте куди швидше 1000000n.
Автор: https://studfile.net




Немає коментарів:
Дописати коментар